

Simform
212 tokens per second - llama-2-13b. Its likely that you can fine-tune the Llama 2-13B model using LoRA or QLoRA fine-tuning with a single consumer. A notebook on how to fine-tune the Llama 2 model with QLoRa TRL and Korean text classification dataset. Llama 2 is broadly available to developers and licensees through a variety of hosting providers and on the. The model you use will vary depending on your hardware. 7b models generally require at least 8GB of RAM 13b models generally require at least. Llama 2-Chat models stem from the foundational Llama 2 models Contrary to GPT-4 which extended its context..
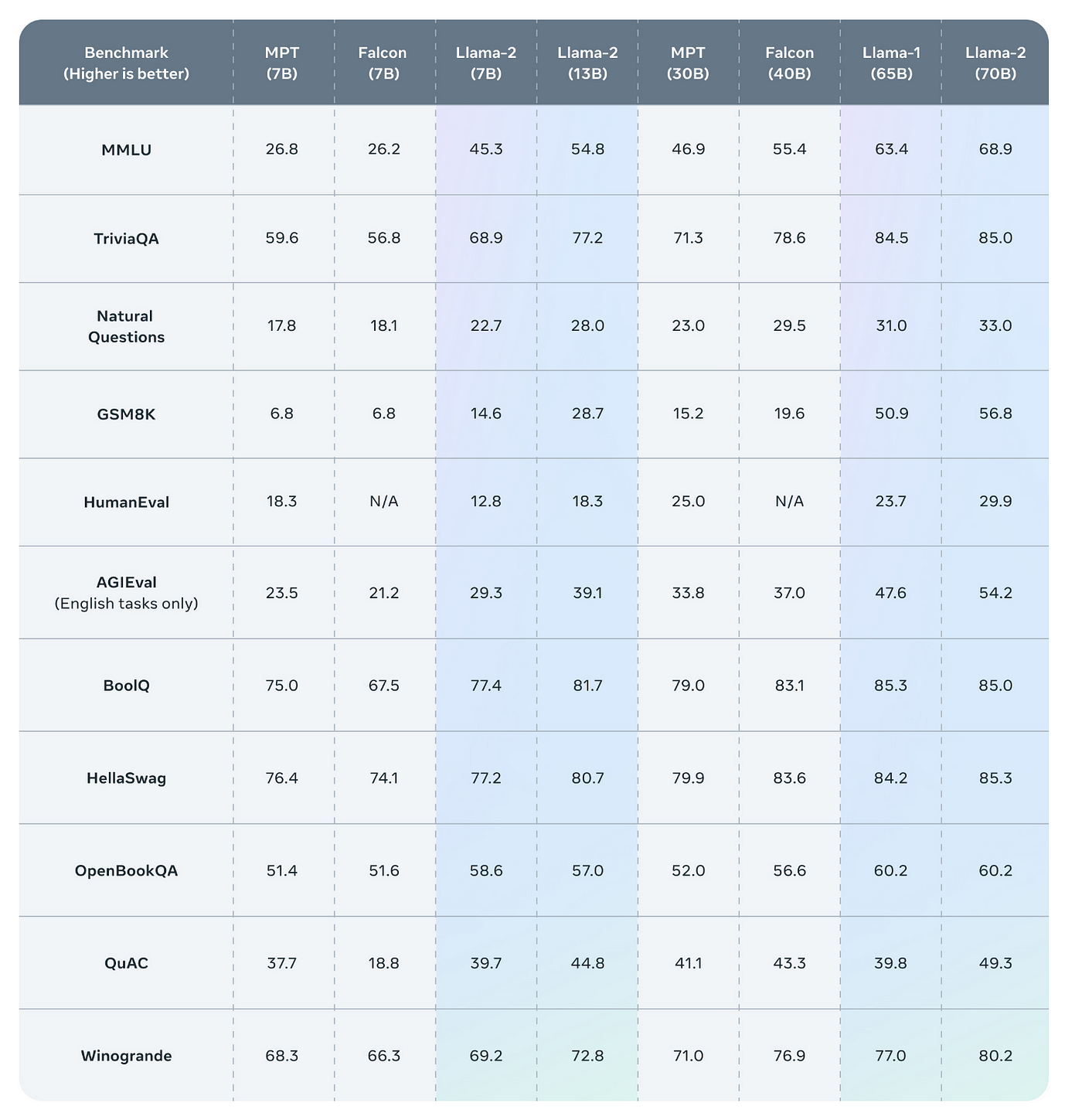
Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters. Amazon Web Services AWS provides multiple ways to host your Llama models In this document we are going to. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine. Llama 2 outperforms other open source language models on many external benchmarks including reasoning coding proficiency and knowledge tests. Install Visual Studio 2019 Build Tool To simplify things we will use a one-click installer for Text-Generation-WebUI the program used..
Medium
Code Llama is a family of state-of-the-art open-access versions of Llama 2 specialized on code tasks and were excited to release. Code Llama This organization is the home of the Code Llama models in the Hugging Face Transformers format Code Llama is a code-specialized version of. Llama 2 is being released with a very permissive community license and is available for commercial use. To deploy a Codellama 2 model go to the huggingfacecocodellama relnofollowmodel page and. The code of the implementation in Hugging Face is based on GPT-NeoX here The original code of the authors can be found here..
Llama 2 encompasses a series of generative text models that have been pretrained and fine-tuned varying in size from 7 billion to 70 billion parameters. Model Developers Meta Variations Llama 2 comes in a range of parameter sizes 7B 13B and 70B as well as pretrained and fine-tuned variations. Completely loaded on VRAM 6300MB took 12 seconds to process 2200 tokens generate a summary 30 tokenssec. The Llama2 7B model on huggingface meta-llamaLlama-2-7b has a pytorch pth file consolidated00pth that is 135GB in size The hugging face transformers compatible model meta. You can access the Metas official Llama-2 model from Hugging Face but you have to apply for a request and wait a couple of days to get confirmation..



Comments